Google Technology....Unearthed..

Google, Inc. (NASDAQ: GOOG and LSE: GGEA) is an American public corporation, first incorporated as a privately held corporation on 7 September 1998, that designed and manages the Internet's most used search engine. The company has approximately 8,000 employees and is based in Mountain View, California. Eric Schmidt, former chief executive officer of Novell, was named Google's CEO when co-founder Larry Page stepped down.
The name "Google" originated from a misspelling of "googol,"which refers to 10100 (a 1 followed by one-hundred zeros). Google has had a major impact on online culture. The verb "google" was recently added to both the Merriam Webster Collegiate Dictionary and the Oxford English Dictionary, meaning "to use the Google search engine to obtain information on the Internet."
Google began as a research project in January, 1996 by Larry Page and Sergey Brin, two Ph.D. students at Stanford University, California. They hypothesized that a search engine that analyzed the relationships between websites would produce better results than existing techniques (existing search engines at the time essentially ranked results according to how many times the search term appeared on a page). It was originally nicknamed "BackRub" because the system checked backlinks to estimate a site's importance. A small search engine called RankDex was already exploring a similar strategy.
Google, being the most popular Internet search engine (over 50% market share), requires large computational resources in order to provide their service. This article describes Google's technological infrastructure, as presented in the company's public announcements.

Network topology
Google maintains an estimated 450,000 servers, arranged in racks located in clusters in cities around the world, with major centers in Mountain View, California; Virginia; Atlanta, Georgia; Dublin, Ireland; and a new facility constructed in 2006 in The Dalles, Oregon. When an attempt to connect to Google is made, Google's DNS servers perform load balancing to allow the user to access Google's content most rapidly. This is done by sending the user the IP address of a cluster that is not under heavy load, and is geographically proximate to them. Each cluster has a few thousand servers, and upon connection to a cluster further load balancing is performed by hardware in the cluster, in order to send the queries to the least loaded Web Server. This make Google one of the biggest and most complex known Content Delivery Network.
Racks are custom-made and contain 40 to 80 servers (20 to 40 1U servers on either side), new servers are 2U Rackmount systems. Each rack has a switch. Servers are connected via a 100 Mbit/s Ethernet link to the local switch. Switches are connected to core gigabit switch using one or two gigabit uplinks.
Server types
Google's server infrastructure is divided in several types, each assigned to a different purpose:
- Google DNS Servers answer the DNS requests and serve as intelligent, worldwide load-balancer. They guess the data center nearest to the user to speed up all http requests.
- Google Web Servers coordinate the execution of queries sent by users, then format the result into an HTML page. The execution consists of sending queries to index servers, merging the results, computing their rank, retrieving a summary for each hit (using the document server), asking for suggestions from the spelling servers, and finally getting a list of advertisements from the ad server.
Server hardware and software
Original hardware
The original hardware (ca. 1998) that was used by Google when it was located at Stanford University, included:
- Sun Ultra II with dual 200MHz processors, and 256MB of RAM. This was the main machine for the original Backrub system.
- 2 x 300 MHz Dual Pentium II Servers donated by Intel, they included 512MB of RAM and 9 x 9GB hard drives between the two. It was on these that the main search ran.
- F50 IBM RS/6000 donated by IBM, included 4 processors, 512MB of memory and 8 x 9GB hard drives.
- Two additional boxes included 3 x 9GB hard drives and 6 x 4GB hard drives respectively (the original storage for Backrub). These were attached to the Sun Ultra II.
- IBM disk expansion box with another 8 x 9GB hard drives donated by IBM.
- Homemade disk box which contained 10 x 9GB SCSI hard drives.
Current hardware
Servers are commodity-class x86 PCs running customized versions of GNU/Linux. Indeed, the goal is to purchase CPU generations that offer the best performance per unit of power, not absolute performance. Other than wages, the biggest cost that Google faces is electric power consumption. Estimates of the power required for over 450,000 servers range upwards of 20 megawatts, which could cost on the order of US$2 million per month in electricity charges.
For this reason, the Pentium II has been the most favoured processor, but this could change in the future as processor manufacturers are increasingly limited by the power output of their devices.
Specifications:
The exact size and whereabouts of the data centers Google uses are unknown, and official figures remain intentionally vague. In a 2000 estimate, Google's server farm consisted of 6000 processors, 12,000 common IDE disks (2 per machine, and one processor per machine), at four sites: two in Silicon Valley, California and two in Virginia.[3] Each site had an OC-48 (2488 Mbit/s) internet connection and an OC-12 (622 Mbit/s) connection to other Google sites. The connections are eventually routed down to 4 x 1 Gbit/s lines connecting up to 64 racks, each rack holding 80 machines and two ethernet switches.
Project 02
Google is currently developing a supercomputer at a data center located in the town of The Dalles, Oregon, on the Columbia River, approximately 80 miles from Portland. The project, codenamed Project 02, is expected to substantially add to their current global network capable of processing billions of search queries per day and a growing repertoire of other services. The new complex is approximately the size of two football fields with cooling towers four stories high. The project has already created hundreds of jobs in the area, mainly construction jobs at this point, with an expected 60 to 200 permanent positions later this year. Real estate prices in the small town of 12,000 have also increased by 40%.
Server operation
Most operations are read-only. When an update is required, queries are redirected to other servers, so as to simplify consistency issues. Queries are divided into sub-queries, where those sub-queries may be sent to different ducts in parallel, thus reducing the latency time.
In order to avoid the effects of unavoidable hardware failure, data stored in the servers may be mirrored using hardware RAID. Software is also designed to be fault tolerant. Thus when a system goes down, data is still available on other servers, which increases the reliability.
- Data-gathering servers are permanently dedicated to spidering the Web. They update the index and document databases and apply Google's algorithms to assign ranks to pages.
- Index servers each contain a set of index shards. They return a list of document IDs ("docid"), such that documents corresponding to a certain docid contain the query word. These servers need less disk space, but suffer the greatest CPU workload.
- Document servers store documents. Each document is stored on dozens of document servers. When performing a search, a document server returns a summary for the document based on query words. They can also fetch the complete document when asked. These servers need more disk space.
- Ad servers manage advertisements offered by services like AdWords and AdSense.
- Spelling servers make suggestions about the spelling of queries.
PageRank is a patented method to assign a numerical weighting to each element of a hyperlinked set of documents, such as the World Wide Web, with the purpose of "measuring" its relative importance within the set. The algorithm may be applied to any collection of entities with reciprocal quotations and references. The numerical weight that it assigns to any given element E is also called the PageRank of E and denoted by PR(E).
PageRank was developed at Stanford University by Larry Page (hence the name Page-Rank [Vise and Malseed, 2005]) and Sergey Brin as part of a research project about a new kind of search engine. The project started in 1995 and led to a functional prototype, named Google, in 1998. Shortly after, Page and Brin founded Google Inc., the company behind the Google search engine. While just one of many factors which determine the ranking of Google search results, PageRank continues to provide the basis for all of Google's web search tools.
Some algorithm details
PageRank is a probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page. PageRank can be calculated for any-size collection of documents. It is assumed in several research papers that the distribution is evenly divided between all documents in the collection at the beginning of the computational process. The PageRank computations require several passes, called "iterations", through the collection to adjust approximate PageRank values to more closely reflect the theoretical true value.
A probability is expressed as a numeric value between 0 and 1. A 0.5 probability is commonly expressed as a "50% chance" of something happening. Hence, a PageRank of 0.5 means there is a 50% chance that a person clicking on a random link will be directed to the document with the 0.5 PageRank.
Simplified PageRank algorithm
Suppose a small universe of four web pages: A, B,C and D. The initial approximation of PageRank would be evenly divided between these four documents. Hence, each document would begin with an estimated PageRank of 0.25.
If pages B, C, and D each only link to A, they would each confer 0.25 PageRank to A. All PageRank PR( ) in this simplistic system would thus gather to A because all links would be pointing to A.

But then suppose page B also has a link to page C, and page D has links to all three pages. The value of the link-votes is divided among all the outbound links on a page. Thus, page B gives a vote worth 0.125 to page A and a vote worth 0.125 to page C. Only one third of D's PageRank is counted for A's PageRank (approximately 0.081).
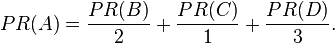
In other words, the PageRank conferred by an outbound link L( ) is equal to the document's own PageRank score divided by the normalized number of outbound links (it is assumed that links to specific URLs only count once per document).

PageRank algorithm including damping factor
The PageRank theory holds that even an imaginary surfer who is randomly clicking on links will eventually stop clicking. The probability, at any step, that the person will continue is a damping factor d. Various studies have tested different damping factors, but it is generally assumed that the damping factor will be set around 0.85.
The damping factor is subtracted from 1 (and in some variations of the algorithm, the result is divided by the number of documents in the collection) and this term is then added to the product of (the damping factor and the sum of the incoming PageRank scores).
That is,

or (N = the number of documents in collection)

So any page's PageRank is derived in large part from the PageRanks of other pages. The damping factor adjusts the derived value downward. The second formula above supports the original statement in Page and Brin's paper that "the sum of all PageRanks is one". Unfortunately, however, Page and Brin gave the first formula, which has led to some confusion.
Google recalculates PageRank scores each time it crawls the Web and rebuilds its index. As Google increases the number of documents in its collection, the initial approximation of PageRank decreases for all documents.
The formula uses a model of a random surfer who gets bored after several clicks and switches to a random page. The PageRank value of a page reflects the chance that the random surfer will land on that page by clicking on a link. It can be understood as a Markov chain in which the states are pages, and the transitions are all equally probable and are the links between pages.
If a page has no links to other pages, it becomes a sink and therefore terminates the random surfing process. However, the solution is quite simple. If the random surfer arrives at a sink page, it picks another URL at random and continues surfing again.
When calculating PageRank, pages with no outbound links are assumed to link out to all other pages in the collection. Their PageRank scores are therefore divided evenly among all other pages. In other words, to be fair with pages that are not sinks, these random transitions are added to all nodes in the Web, with a residual probability of usually d = 0.85, estimated from the frequency that an average surfer uses his or her browser's bookmark feature.
So, the equation is as follows:

where p1,p2,...,pN are the pages under consideration, M(pi) is the set of pages that link to pi, L(pj) is the number of links coming from page pj, and N is the total number of pages.
The PageRank values are the entries of the dominant eigenvector of the modified adjacency matrix. This makes PageRank a particularly elegant metric: the eigenvector is
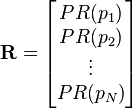
where R is the solution of the equation
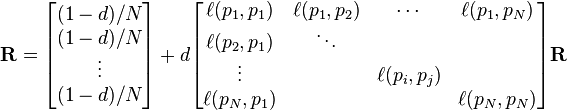
where the adjacency function 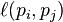 is 0 if page pj does not link to pi, and normalised such that, for each j
is 0 if page pj does not link to pi, and normalised such that, for each j
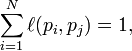
i.e. the elements of each column sum up to 1.
This is a variant of the eigenvector centrality measure used commonly in network analysis.
The values of the PageRank eigenvector are fast to approximate (only a few iterations are needed) and in practice it gives good results.
As a result of Markov theory, it can be shown that the PageRank of a page is the probability of being at that page after lots of clicks. This happens to equal t − 1 where t is the expectation of the number of clicks (or random jumps) required to get from the page back to itself.
The main disadvantage is that it favors older pages, because a new page, even a very good one, will not have many links unless it is part of an existing site (a site being a densely connected set of pages). The Google Directory (itself a derivative of the Open Directory Project) is an exception in which PageRank is not used to determine search results rankings.
Several strategies have been proposed to accelerate the computation of PageRank.
Various strategies to manipulate PageRank have been employed in concerted efforts to improve search results rankings and monetize advertising links. These strategies have severely impacted the reliability of the PageRank concept, which seeks to determine which documents are actually highly valued by the Web community.
Google is known to actively penalize link farms and other schemes designed to artificially inflate PageRank. How Google identifies link farms and other PageRank manipulation tools are among Google's trade secrets.
False or spoofed PageRank
While the PR shown in the Toolbar is considered to be accurate (at the time of publication by Google) for most sites, it must be noted that this value is also easily manipulated. A current flaw is that any low PageRank page that is redirected, via a 302 server header or a "Refresh" meta tag, to a high PR page causes the lower PR page to acquire the PR of the destination page. In theory a new, PR0 page with no incoming links can be redirected to the Google home page - which is a PR 10 - and by the next PageRank update the PR of the new page will be upgraded to a PR10. This is called spoofing and is a known failing or bug in the system. Any page's PR can be spoofed to a higher or lower number of the webmaster's choice and only Google has access to the real PR of the page. Spoofing is generally detected by running a Google search for a URL with questionable PR, as the results will display the URL of an entirely different site (the one redirected to) in its results.
Google's home page is often considered to be automatically rated a 10/10 by the Google Toolbar's PageRank feature, but its PageRank has at times shown a surprising result of only 8/10.
Source
www.wikipedia.org
AJAX
This is what GOOGLE is Based ON...
Ajax, shorthand for Asynchronous JavaScript and XML, is a web development technique for creating interactive web applications. The intent is to make web pages feel more responsive by exchanging small amounts of data with the server behind the scenes, so that the entire web page does not have to be reloaded each time the user makes a change. This is meant to increase the web page's interactivity, speed, and usability.
The Ajax technique uses a combination of:
Like DHTML, LAMP and SPA, Ajax is not a technology in itself, but a term that refers to the use of a group of technologies together.
Pros
Bandwidth utilization
By generating the HTML locally within the browser, and only bringing down JavaScript calls and the actual data, Ajax web pages can appear to load quickly since the payload coming down is much smaller in size. An example of this technique is a large result set where multiple pages of data exist. With Ajax, the HTML of the page, e.g., a table control and related TD and TR tags can be produced locally in the browser and not brought down with the first page of data. If the user clicks other pages, only the data is brought down, and populated into the HTML generated in the browser.
Interactivity
Ajax applications are mainly executed on the user's machine, by manipulating the current page within their browser using document object model methods. Ajax can be used for a multitude of tasks such as updating or deleting records; expanding web forms; returning simple search queries; or editing category trees—all without the requirement to fetch a full page of HTML each time a change is made. Generally only small requests need to be sent to the server, and relatively short responses are sent back. This permits the development of more interactive applications featuring more responsive user interfaces due to the use of DHTML techniques.
While the Ajax platform is more restricted than the Java platform, current Ajax applications effectively fill part of the niche first served by Java applets: extending the browser with lightweight mini-applications.
Cons
Complex to learn.



 Now you only need to save the file using the usual Right Click - Save As method
Now you only need to save the file using the usual Right Click - Save As method